AI绘画是通过扩散模型(Diffusion Models)或生成对抗网络(GANs)将文本语义映射为视觉像素的计算艺术。截至2026年3月,该技术已从早期的“随机抽卡”进化为可实现像素级控制的生产力工具。
其本质是对人类视觉经验的数学重构,而非传统意义上的“创作”。AI在概率空间中寻找最符合描述的像素分布,这解释了为什么它在处理逻辑严密、结构精确的图像时仍有随机性,但其交付效率已彻底改写商业美术的周期。
核心原理:从噪声到图像的逆向还原
AI绘画的核心在于“去噪”。以扩散模型为例,流程分为前向加噪和反向去噪。前向阶段将清晰图像逐渐变为随机高斯噪声;训练过程中,AI学习如何在每一步剔除噪声以还原原图。
当输入“赛博朋克街道上的金毛犬”时,AI并非在数据库中检索图片,而是在噪声画布上,根据文本引导(Text Guidance)剔除不符合特征的像素。通过U-Net架构和注意力机制,图像的局部细节与全局构图得以在逻辑上保持一致。这种将概率论转化为视觉美感的过程虽然冰冷,但结果极其惊艳。
Midjourney v7 商业级控图实操

2026年的商业需求已不再满足于简单的提示词,需采用“结构引导 + 局部重绘 + 参数调优”的组合方案。
--sref 指令配合图片链接(格式:/imagine [文本描述] --sref [图片URL])。由于AI对“左边/右边”等方位描述的理解仍不稳定,提供简单的线条草图可将其作为几何权重底稿,文本则负责填充材质和光影。若构图偏离,可将 --sw(Style Weight)调至 800 以上增强约束。
--v 7 指定版本,--ar 16:9 设置画幅。其中 --stylize 参数决定了作品的艺术化程度:数值越高,AI介入的美学理解越多,可能偏离原意;数值越低,则越忠实于提示词。商业产品图建议设在 100-200 之间。最后通过 Upscale (Subtle) 或 (Creative) 放大至 8K 分辨率。
AI与传统艺术:类比摄影的逻辑
AI对画师的冲击,实际上是 19 世纪摄影术对绘画影响的数字化重演。相机出现后,写实绘画虽失去垄断地位,但迫使艺术家转向印象派、立体派等深层探索。
AI目前扮演的是“高效记录者”角色。它提供了极强的执行力,但缺乏审美判断力。因此,艺术家的竞争力正在从“如何画”转移到“定义什么”。优秀的AI艺术家更像导演,把控光影、情绪和叙事,将像素填充交给机器。
主流工具对比分析

目前市场上的主流AI绘画工具在美学、控制力与合规性之间各有侧重:
| 工具名称 | 核心特点 | 适用场景 | 付费模式 |
|---|---|---|---|
| Midjourney | 美学上限极高,出图自带“高级感” | 概念图、广告创意、快速视觉验证 | 月费订阅 ($10-60) |
| Stable Diffusion | 开源生态,精准控制(LoRA/ControlNet) | 专业原画、电商模特、私有化部署 | 免费 (需自备GPU) |
| Adobe Firefly | 版权合规,与 PS 工作流无缝衔接 | 企业级修图、版权敏感项目 | Adobe 套餐计费 |
AI绘画的局限性与风险
尽管能力强大,但在实际商业应用中仍需警惕以下三大痛点:
- 高精度工业设计: AI擅长生成“看起来正确”的图,但在毫米级机械结构中常出现逻辑错误,导致工程失效。
- 情感唯一性创作: AI的本质是“平均值”,容易将颠覆性的视觉语言拉回大众审美的舒适区,抹杀创新灵气。
- 版权法律风险: 纯 AI 生成的作品在很多国家仍难以获得法律意义上的版权保护。建议最终定稿必须由人类进行二次创作和矢量化重构。
进阶:建立私有化视觉资产库(LoRA 训练)
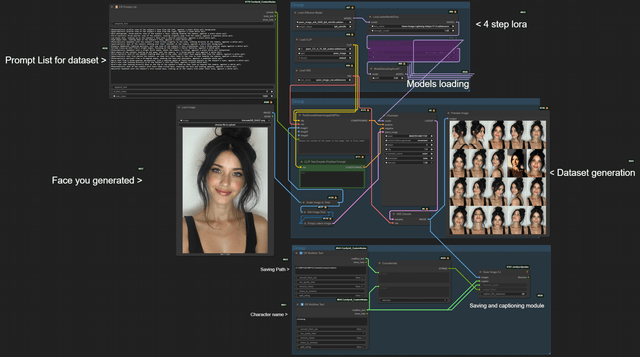
对于需要长期维持视觉统一的项目(如游戏角色),可通过训练 LoRA 模型让 AI 记住特定特征。
<lora:MyCharacter:0.7>进化建议:从图像生成转向视觉理解
未来的趋势是“可编辑的语义空间”,即在三维空间调整物体位置,AI 实时渲染高质量二维图像,实现所见即所得。这要求创作者将重心回归到观察力、哲学思考和情感捕捉上。
建议采取“1+1”策略:用 Midjourney 快速验证创意,用 Stable Diffusion/ComfyUI 深挖控制力。尝试将现有项目进行“概念扩充”——用 AI 生成 50 个草图方向 $\rightarrow$ 人类筛选灵感 $\rightarrow$ 手动精修。这种闭环是目前最高效且最具掌控力的创作模式。
AI 绘画会完全取代原画师吗?
不会,但会取代“只会执行且无审美”的画师。AI 降低了绘画的门槛,但提高了对“审美定义权”和“复杂工作流把控力”的要求。原画师将演变为视觉导演。
如何解决 AI 生成图像中的文字乱码问题?
虽然 v7 版本在文字理解上有极大进步,但对于复杂排版,建议生成无字底图,再通过 Photoshop 或 AI 矢量化工具进行后期文字叠加,以确保商业级精确度。
LoRA 训练时图片数量越多越好吗?
并非如此。质量远比数量重要。20 张极致精选、标注准确的图片效果通常优于 200 张含有噪声或风格不统一的图片,过多低质图片会导致模型泛化能力下降。