AI 降噪是通过机器学习模型识别并分离信号(图像或音频)中的杂讯,在剔除噪声的同时利用预测算法重建丢失细节的技术。它通过海量数据集训练,使机器能够分辨“纯净信号”与“噪声”,从而实现精准剥离,而非依赖传统的频率过滤或模糊处理。
到 2026 年 3 月,AI 降噪已分化为两个技术维度:视觉层面的像素重建与听觉层面的频谱修复。两者的底层逻辑与解决的痛点完全不同。
第一部分:视觉 AI 降噪的逻辑与实操
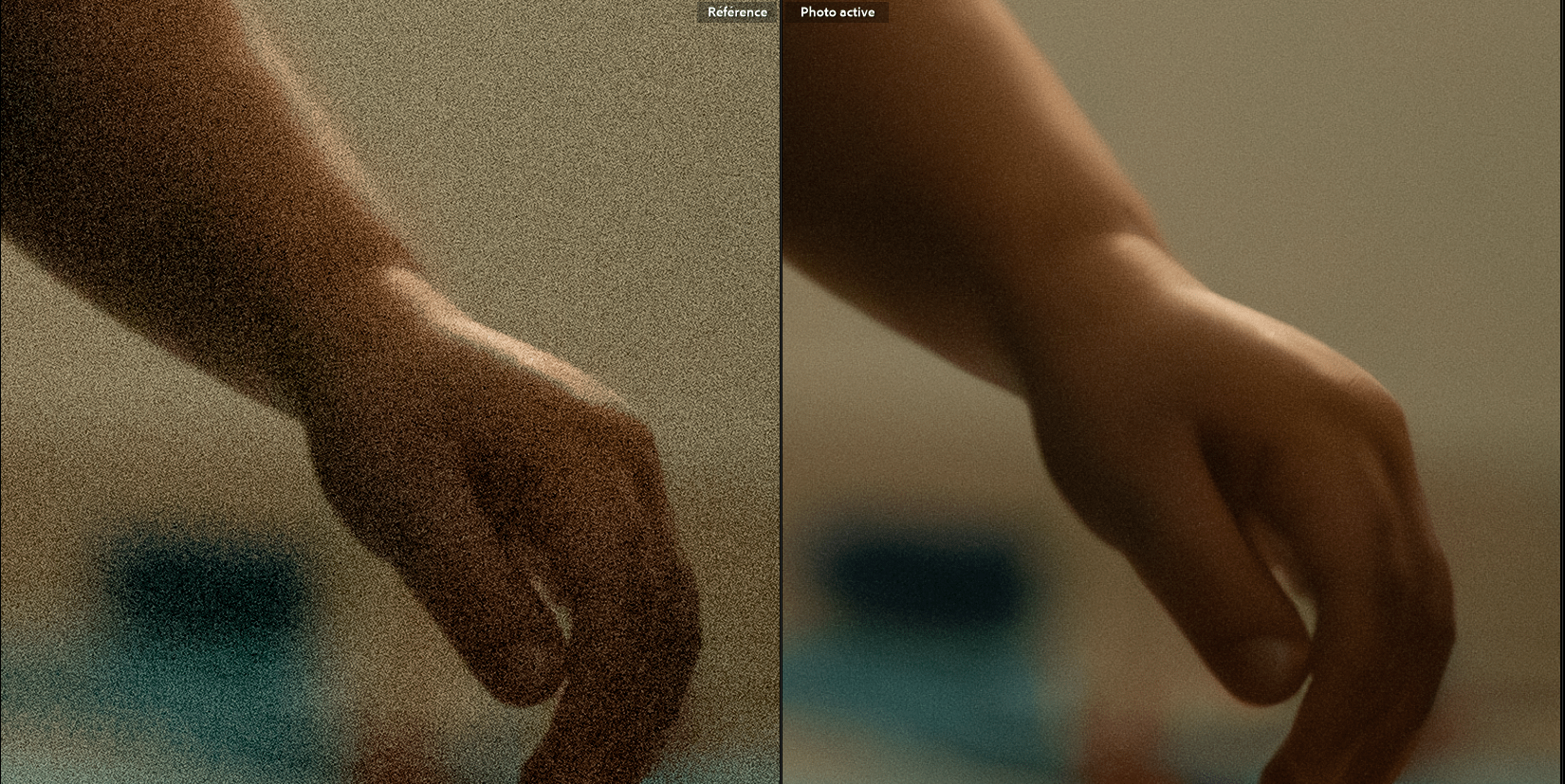
视觉降噪旨在解决高 ISO 拍摄产生的随机噪声和彩色噪点。传统降噪类似“大刷子”,在抹除噪点的同时会损失细节,导致画面出现涂抹感。而基于深度卷积神经网络(CNN)的工具,本质是在进行细节的“预测”与“填充”。
最高效的视觉降噪链路是:RAW 预处理 $\rightarrow$ AI 降噪 $\rightarrow$ 后期调色。如果先导出为 JPG 再降噪,由于压缩算法已将噪点与图像信息融合,AI 将难以区分真实纹理与噪声。直接处理 RAW 文件能最大限度提升信噪比。
以下是以 DxO PureRAW 为例的商业级画质处理流程:

第二部分:音频 AI 降噪的逻辑与实操
音频降噪的难点在于剔除杂讯的同时保留音调,避免人声出现“水下感”。目前的音频降噪已从简单的门限过滤进化为实时语音分离(Speech Separation)。
工具分为实时处理(如 NVIDIA Broadcast)和后期精修(如 iZotope RX 或 UniConverter)。对于播客或视频创作者,通过识别环境声“指纹”并将其从频谱中扣除的后期精修更为关键。
针对含强背景底噪的录音,建议采取以下修复步骤:
第三部分:主流 AI 降噪工具对比

不同工具在处理逻辑和适用场景上存在显著差异,用户需根据素材类型选择合适工具。
| 维度 | 代表工具 | 核心优势 | 主要短板 |
|---|---|---|---|
| 视觉降噪 | DxO PureRAW | 光学建模精准,效果自然 | 仅支持 RAW,价格较高 |
| Topaz Photo AI | 集成锐化放大,出片快 | 极端环境下易产生 AI 幻觉 | |
| LR AI Denoise | 集成度高,订阅便捷 | 处理速度慢,极高ISO压制力稍弱 | |
| 音频降噪 | UniConverter AI | 速度极快,适合短视频快节奏 | 专业音乐工程细节丢失较多 |
| iZotope RX 系列 | 行业标准,支持手动频谱干预 | 学习曲线陡峭,价格昂贵 | |
| NVIDIA Broadcast | 实时性强且免费,适合直播 | 偶尔出现声音断层(Artifacts) |
第四部分:局限性与风险提示
AI 降噪基于概率预测,并非万能。过度处理会使作品失去“生命感”。
在视觉上,AI 不擅长处理极高频微小细节。当噪点量超过有效信号量时,AI 会通过训练集“填空”,生成的图像是算法认为“应该”的样子而非真实记录,这在法庭证据或商业产品展示中存在风险。此外,极低对比度画面(如夜空、白墙)易出现色块(Banding)。
在音频上,AI 难以处理动态剧烈变化的复杂环境。例如,街道采访中突然的鸣笛声可能导致 AI 在消除噪声时将同步的人声音调强行拉低,产生“声音塌陷”。对于音乐录制,AI 容易破坏乐器的自然泛音,使小提琴失去共鸣感。
若素材质量较差,建议先使用轻量工具,将强度控制在 30%-50% 之间分段处理。务必保留一份未处理的原始副本,因为适度的颗粒感往往比绝对的纯净更能提供自然、真实的现场感。
问:AI 降噪是否会导致图像或音频的真实性受损?
答:是的。由于 AI 是基于模型预测进行“重建”而非简单的“过滤”,在极端参数下会产生 AI 幻觉(如将噪点误认为皮肤毛孔或改变人声音调)。建议在商业交付前对比原片,确保关键细节未被篡改。
问:为什么建议在视觉降噪中优先处理 RAW 文件?
答:因为 JPG 等压缩格式在生成时已经将噪点与图像像素进行了有损融合。AI 在处理 RAW 文件时可以访问原始传感器数据,能够更精准地分离随机噪声与真实纹理,从而获得更高的信噪比。